Problem :
- Our client faced significant inefficiencies in their data loading processes.
- They were manually transferring large datasets from Excel to Azure SQL Database, which was time-consuming and prone to errors.
- This process was affecting their ability to make timely business decisions due to delayed data availability.
Solution :
- We implemented Azure Data Factory to automate and streamline the ETL (Extract, Transform, Load) process. By setting up pipelines, we ensured that data from Excel files could be automatically extracted, transformed as needed, and loaded into Azure SQL Database efficiently. This solution reduced data load times by 50%, minimized manual errors, and provided the client with up-to-date data for quicker decision-making.
Prerequisites
- Azure subscription: If you don’t have an Azure subscription, create a free account before you begin.
- Azure Storage account: Use Blob storage as the source data store. If you don’t have an Azure Storage account, see the instructions in Create a storage account.
- Azure SQL Database: Use a SQL Database as the sink data store. If you don’t have a SQL Database, see the instructions in Create a SQL Database.
Create a source blob
- Create a container named dynamicloadexcelsa and upload the data.xls file to the container.
Create a azure sql database
Use the Azure portal to create the new free Azure SQL Database.
To create your database, follow these steps:
- Go to the Azure portal provisioning page for Azure SQL Database.
- On the Basics tab, look for the banner that says “Want to try Azure SQL Database for free?”, select the Apply offer
- Under Project details, select your Subscription name.
- For Resource group, select Create new, enter your resource group, and select OK.
- For Database name, enter your databasename.
- For Server, select Create new, and fill out the New server form with the following values:
- Server name: Enter your servername, and add some characters for uniqueness. The name of the Azure SQL logical server must be lowercase.
- Authentication method: Select Use both SQL and Microsoft Entra authentication.
- Server admin login: Enter a username for the SQL authentication server admin.
- Password: Enter a password for the SQL authenticated server admin that meets complexity requirements, and enter it again in the Confirm password
- Location: Select a location from the dropdown list.
- Select OK. Leave other options as default.
- Under Compute + storage, leave the existing default database as configured “Standard-series (Gen5), 2 vCores, 32-GB storage”. You can adjust this setting later if needed.
- For the Behavior when free limit reached setting, you have two choices to determine what happens when the free monthly offer limits are exhausted.
- If you choose Auto-pause the database until next month option, you’ll not be charged for that month once the free limits are reached, however the database will become inaccessible for the remainder of the calendar month. Later, you can enable the Continue using database for additional charges setting in the Compute + Storage page of the SQL database.
- To maintain access to the database when limits are reached, which results in charges for any amount above the free offer vCore and storage size limits, select the Continue using database for additional charges You only pay for any usage over the free offer limits.
- You continue to get the free amount renewed at the beginning of each month.
- Select Next : Networking. On the Networking tab, for Firewall rules, set Allow Azure services and resources to access this server set to Yes. Set Add current client IP address to Yes. Leave other options as default.
- Select Next : Security. Leave these options as defaults.
- Select Next: Additional settings. On the Additional settings tab, in the Data source section, for Use existing data, you have options to use an existing database:
- Select Review + create. If you’re starting with the free database offer, you should see a card with no charges on it.
- Review and select Create.
Create a data factory
In this step, you create a data factory and start the Data Factory UI to create a pipeline in the data factory.
- Open Microsoft Edge or Google Chrome. Currently, Data Factory UI is supported only in Microsoft Edge and Google Chrome web browsers.
- On the left menu, select Create a resource > Integration > Data Factory.
- On the Create Data Factory page, under Basics tab, select the Azure Subscription in which you want to create the data factory.
- For Resource Group, take one of the following steps:
- Select an existing resource group from the drop-down list.
- Select Create new, and enter the name of a new resource group.
To learn about resource groups, see Use resource groups to manage your Azure resources.
- Under Region, select a location for the data factory. Only locations that are supported are displayed in the drop-down list. The data stores (for example, Azure Storage and SQL Database) and computes (for example, Azure HDInsight) used by the data factory can be in other regions.
- Under Name, enter your DataFactoryName.
The name of the Azure data factory must be globally unique. If you receive an error message about the name value, enter a different name for the data factory. (for example, yournameADFTutorialDataFactory). For naming rules for Data Factory artifacts, see Data Factory naming rules.
- Under Version, select V2.
- Select Review + create, and select Create after the validation is passed.
- After the creation is finished, you see the notice in Notifications center. Select Go to resource to navigate to the Data factory page.
- Select Open on the Open Azure Data Factory Studio tile to launch the Azure Data Factory UI in a separate tab.
Create a pipeline
In this step, you create a pipeline with a copy activity in the data factory. The copy activity copies data from Blob storage to SQL Database. In the Quickstart tutorial, you created a pipeline by following these steps:
- Create the linked service.
- Create input and output datasets.
- Create a pipeline.
In this tutorial, you start with creating the pipeline. Then you create linked services and datasets when you need them to configure the pipeline.
- On the home page, open your data factory and launch studio.
- Click on the Author option and move to the next step to create pipeline
- In the General panel under Properties, specify CopyPipeline for Name. Then collapse the panel by clicking the Properties icon in the top-right corner.
- In the Activities tool box, expand the Move and Transform category, and drag and drop the Copy Data activity from the tool box to the pipeline designer surface.
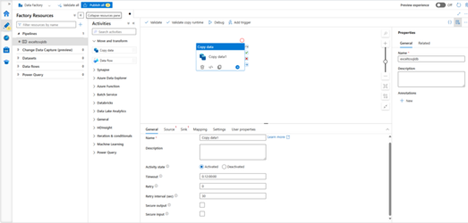
Configure source
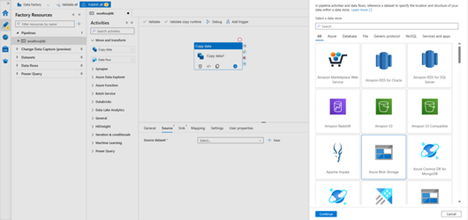
- Go to the Source Select + New to create a source dataset.
- In the New Dataset dialog box, select Azure Blob Storage, and then select Continue. The source data is in Blob storage, so you select Azure Blob Storage for the source dataset.
- In the Select Format dialog box, choose the format type of your data, and then select Continue.
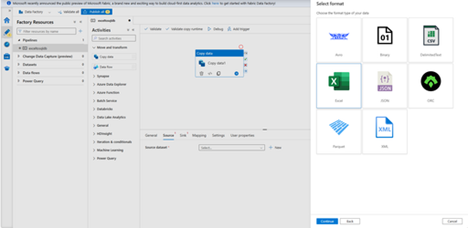
- In the Set Properties dialog box, enter SourceBlobDataset for Name. Select the checkbox for First row as header. Under the Linked service text box, select + New.
- In the New Linked Service (Azure Blob Storage) dialog box, enter AzureStorageLinkedService as name, select your storage account from the Storage account name Test connection, select Create to deploy the linked service.
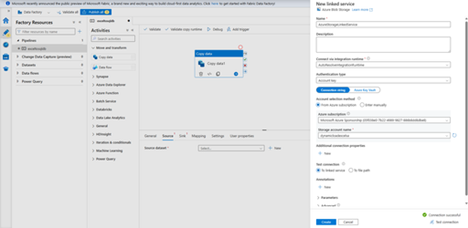
- After the linked service is created, it’s navigated back to the Set properties Next to File path, select Browse.
- Navigate to the demoload folder, select the xls file, and then select OK.
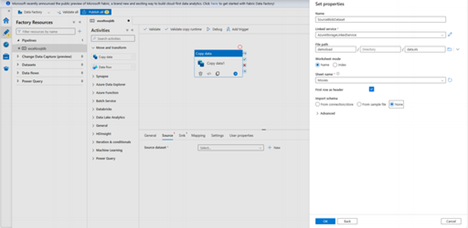
- Select OK. It automatically navigates to the pipeline page. In Source tab, confirm that SourceBlobDataset is selected. To preview data on this page, select Preview data.
Configure sink
- Go to the Sink tab, and select + New to create a sink dataset.
- In the New Dataset dialog box, input “SQL” in the search box to filter the connectors, select Azure SQL Database, and then select Continue. In this tutorial, you copy data to a SQL database.
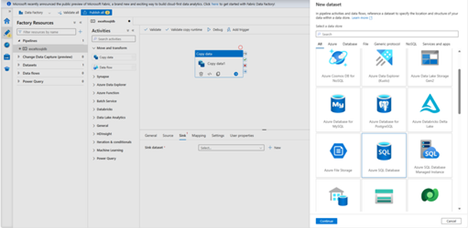
- From the Linked service dropdown list, select + New. A dataset must be associated with a linked service. The linked service has the connection string that Data Factory uses to connect to SQL Database at runtime. The dataset specifies the container, folder, and the file (optional) to which the data is copied.
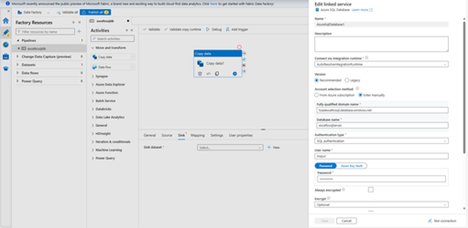
- In the New Linked Service (Azure SQL Database) dialog box, take the following steps:
- Under Name, enter AzureSqlDatabase1.
- Under Server name, select your SQL Server instance.
- Under Database name, select your database.
- Under User name, enter the name of the user.
- Under Password, enter the password for the user.
- Select Test connection to test the connection.
- Select Create to deploy the linked service.
- It automatically navigates to the Set Properties dialog box. In Table, select [test].[movies]. Then select OK.
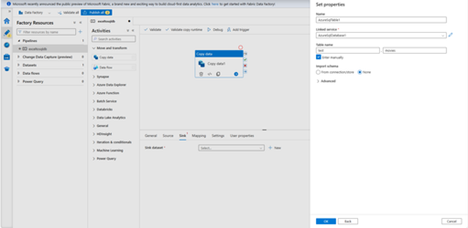
- Go to the tab with the pipeline, and in Sink Dataset, confirm that AzureSqlDatabase1 is selected.
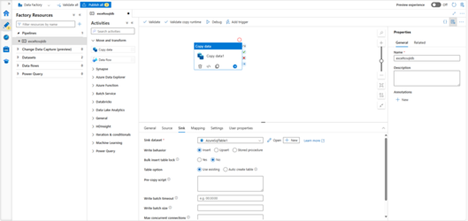
Validate the pipeline
- To validate the pipeline, select Validate from the tool bar.
You can see the JSON code associated with the pipeline by clicking Code on the upper right.
Debug and publish the pipeline
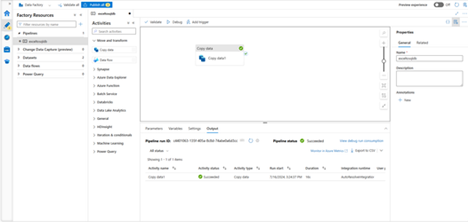
- To debug the pipeline, select Debug on the toolbar. You see the status of the pipeline run in the Output tab at the bottom of the window.
- Once the pipeline can run successfully, in the top toolbar, select Publish all. This action publishes entities (datasets, and pipelines) you created to Data Factory.
- Wait until you see the Successfully published To see notification messages, click the Show Notifications on the top-right (bell button).
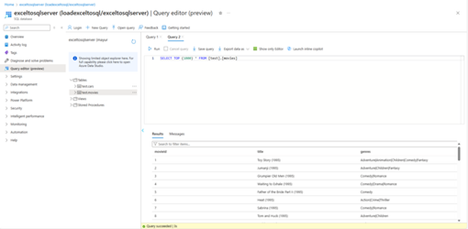
- Verify that more rows are added to the movies table in the database.
Trigger the pipeline on a schedule
In this schedule, you create a schedule trigger for the pipeline. The trigger runs the pipeline on the specified schedule, such as hourly or daily or Weekly. Here you set the trigger to run every week until the specified end datetime.
- Go to the Author tab on the left above the monitor tab.
- Go to your pipeline, click Trigger on the tool bar, and select New/Edit.
- In the Add triggers dialog box, select + New for Choose trigger
- In the New Trigger window, take the following steps:
- Under Name, enter RunEveryFiveMinutes.
- Update the Start date for your trigger. If the date is before current datetime, the trigger will start to take effect once the change is published.
- Under Time zone, select the drop-down list.
- Set the Recurrence to Every 5 Minute(s).
- Select the checkbox for Specify an end date, and update the End On part to be a few minutes past the current datetime. The trigger is activated only after you publish the changes. If you set it to only a couple of minutes apart, and you don’t publish it by then, you don’t see a trigger run.
- For Activated option, select Yes.
- Select OK.
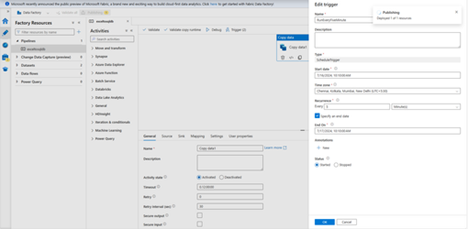
- On the Edit trigger page, review the warning, and then select Save. The pipeline in this example doesn’t take any parameters.
- Click Publish all to publish the change.
- Go to the Monitor tab on the left to see the triggered pipeline runs.

- To switch from the Pipeline Runs view to the Trigger Runs view, select Trigger Runs on the left side of the window.
- You see the trigger runs in a list.